Boring agents by design: how Monk builds reliable agents for AR

Most agent demos are exciting. Production agents that talk to your customers about your money cannot afford to be. We build boring agents by design. Here is why, and how.
The conventional wisdom we reject
Automation came for accounts payable first because paying bills is a process. Accounts receivable stayed human because it is your customers and your money. The usual take is that collections cannot be automated without damaging relationships, so teams keep adding headcount.
We see it differently.
Collections are about communication. It takes judgment to keep cash flow healthy without burning a relationship. Communication is exactly what language models are good at. The catch is that you have to remove the margin of error first.
The one problem in collections
No margin of error is allowed with an agent that talks to your customers about your money.
An agent that is right 95% of the time still fails in production. The 5% is the agent misstating a balance, inventing a discount, or taking the wrong tone with a customer worth far more than the invoice.
For example, if a collections thread comes back with a reply asking to send the next payment to a new bank account, a naive agent reads it and acts on it. That is exactly how payment redirect fraud works. Our agent will not act. It flags the change and hands it to a person.
The stakes are real because the agents are good enough to seem like a trusted human, and as a result they hold actual conversations with our customers’ customers about money that is owed. People reply to them, invite them to calls, and try to add them on LinkedIn. When an agent is that convincing, a single wrong move carries the weight of a real one.
The nuclear navy got here first
Zero margin of error is not a new standard. Adiral Hyman Rickover spent 63 years in the US Navy and built its nuclear propulsion program. Over 100 reactors, run across decades, with zero reactor accidents. The Soviet program, by contrast, had at least ten, several of them fatal.
The difference was not smarter engineers. It was an uncompromising obsession with checks, standards, and rules. That is the bar we hold ourselves to in AR.
Our approach: treat LLMs like toddlers
In high-stakes production workflows we treat language models like toddlers. We give them a small, well-defined space to operate in, and we watch the edges. In practice that is three things: opinionated design, tests, and guardrails.
1. Opinionated design
The model gets a narrow pane to decide in. Everything around it is structured and deterministic:
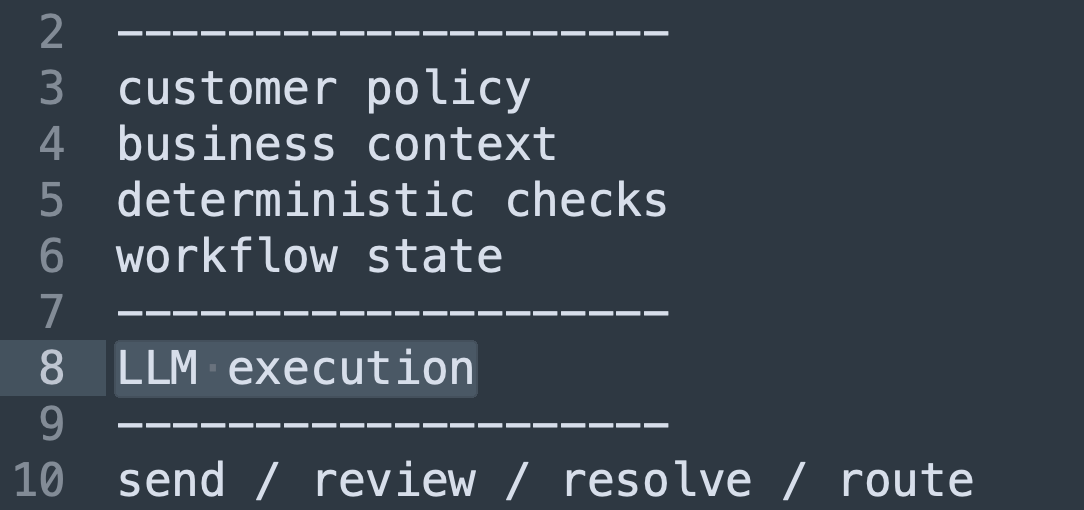
The model executes inside that frame, and its output is limited to a small set of moves: send, review, resolve, or route. It cannot freelance. It chooses from actions we have already decided are safe.
On top of that sit playbooks. Collections is not one motion, so we route by account value and situation. High-value accounts get a softer, human-backed touch. Lower-value accounts run a mostly automated email cadence. Disputes, no-pays, and anything ambiguous route straight to a person. The model follows the playbook. It does not write its own.
2. Tests
We test against what actually happens, not against benchmarks.
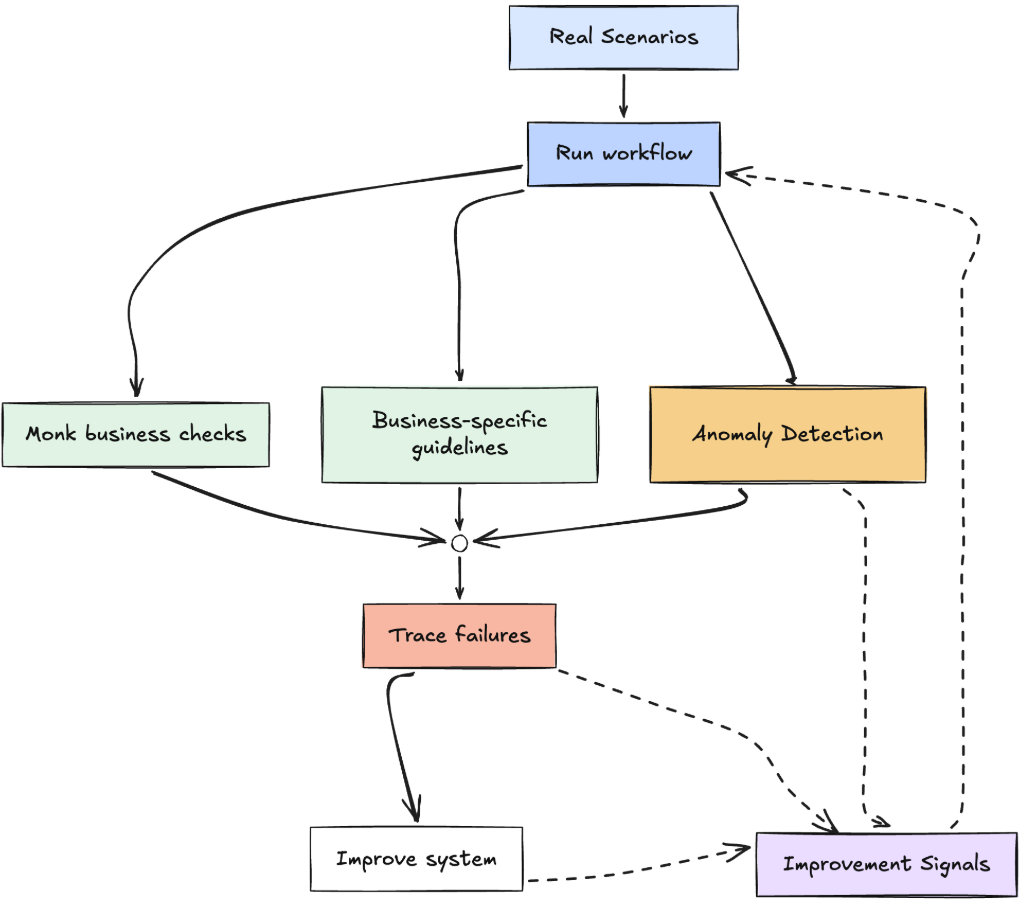
We run the workflow against real scenarios and check every run three ways: Monk’s own business checks, the business-specific guidelines for that customer, and anomaly detection. When a run fails a check, we trace the failure, fix the system, and feed the signal back in so the next run is better. It is a loop, not a launch.
3. Guardrails
When in doubt, the agent escalates. It never guesses.
Anomaly detection runs on every interaction. Disputes, escalations to senior people off the chain, or issues with the product may also trigger it, and the triggers vary by customer. The agent’s job in those moments is not to be clever. It is to hand off cleanly, with the full context attached.
When the agent acts vs. when it escalates
The agent acts when:
- the data is verified against the ledger
- the playbook covers the scenario
- the next step is routine: a reminder, sharing verified payment details, marking an invoice resolved, or routing to the right owner
The agent escalates when:
- someone asks to change payment or bank details
- there is a dispute or a partial payment
- sentiment turns negative
- anything falls outside the playbook
The trade-offs we accept
Boring agents demo worse. Constraints mean the agent does less than the model could. We are fine with that. In systems that have to be reliable, and AR is one, boring works. Reliability is the feature.
Results
We are biased, but the approach is working. Customers go live in 1 to 3 days on average, and 88.2% of invoices resolved without escalation to an end user. Early days. Long way to go.
Where this goes
The models will keep getting smarter. Eventually the harness will be mostly about data and context, and less about the rails we build today. But we have to graduate to that world. Until we do, we do not skip the discipline. We treat the model with caution and obsess over guardrails the same way Rickover obsessed over reactor safety.
Boring, but reliable. That is the bet.
See how Monk handles collections, cash application, and forecasting at intelligent collections, or book a demo. Interested in building with us? We are looking for stellar engineers, more here.


.avif)